최근 들어 딥러닝이 큰 화두가 되었고, 다양한 구조와 방법론이 제시되었습니다. 딥러닝은 점점 더 다양한 주제의 문제를 다룰 수 있게 되었고, 이에 맞춰 다양한 딥러닝 구조가 제시되었습니다. 모델의 성능 향상 또한 지속해서 이루어졌습니다. 그리고 성능 향상을 위해 레이어를 깊게 쌓는 것은 보편화되어 있는 방법입니다.
그러나 이러한 발전은 통계 기법의 입장에서는 받아들이기 어려운 부분입니다. 왜냐하면 레이어를 깊게 쌓는다는 것은 모델 파라메터가 많아진다는 것이고, 일반적으로 필요 이상의 과한 파라메터 개수는 모델 성능 저하를 일으키기 때문입니다. 그럼에도 현실적으로, 많은 문제에 대해서 레이어를 깊게 쌓음으로써 모델 성능 향상이 이루어졌습니다.
그래서 연구자들은 이러한 현상을 이해하기 위해 다양한 연구를 진행했습니다. 한편 이 논문은 이러한 현상을 수학적으로 해석해보거나 또는 한계를 파악해보고자 했던 논문입니다. 정말 그냥 대충 요약하면 결론은, 수학적으로 서로 다른 두 뉴럴 네트워크가 같은 결과를 출력하는 경우는 생각보다 많지 않다는 것입니다.
조건도 많고 명제도 길지만 결론적으로 얘기하는 것은 똑같은 구조의 ReLU Network 가 동일한 입력에 대해 동일한 출력을 갖기 위해서는 각 레이어가 Permutation Matrix(각 노드의 순서를 바꾸는 행렬) 과 Positive Diagonal Matrix(각 노드 값의 양의 배수를 취하는 행렬)으로 서로 변환될 수 있어야 한다는 의미입니다.
즉, 행렬이 가질 수 있는 자유도(?)를 생각해봤을 때, 두 네트워크가 같은 값을 가지는 경우는 많지 않다는 것을 증명하는 명제입니다. 주의해야 할 점은 위 명제에서 한정하는 네트워크 구조는 가장 단순한 Feed Forward 네트워크 구조입니다. CNN, Residual, RNN 등의 구조는 위 명제에 대해 증명되지 않았습니다. 또한 활성화 함수 또한 ReLU여야 합니다.
명제를 증명하기 위해 몇 가지 가정이 존재합니다. Z(입력값 범위)가 open nonempty 여야 하고, 레이어 넓이가 non-increasing 이어야 합니다. 또한 마지막 hidden layer 의 넓이가 2 이상이어야 합니다. 위 가정은 명제를 증명함에 있어 필요한 가정입니다.
그리고 'general' ReLU network 라는 개념이 등장합니다. 이 개념에 대한 소개는 아래에 다루도록 하겠습니다.
저자는 위 명제를 바탕으로 서로 다른 두 ReLU network 가 동일한 출력을 만드는 경우가 생각보다 많지 않으며, over parametrization 에 따른 parameterization redundancy 가 적다고 이야기 합니다. 이러한 결론은 일반적인 생각과 모순되는데, 이는 아래와 같은 다양한 이유로 설명될 수 있다고 합니다.
위 명제를 증명하기 위해 필요한 개념과 보조 정리를 소개합니다. 위 명제를 증명하기 위해 다양한 개념을 설정하는 데, 천천히 읽으며 이해한다면 그 나름의 재미를 느낄 수가 있습니다.
위 명제를 이해하기 위해 General ReLU network 를 알아야 합니다. General ReLU network 를 소개하기에 앞서 이 논문에서 말하는 ReLU network 가 무엇인지 소개합니다.
ReLU NetowrkLet Z⊆Rd0 with d0≥2 be a nonempty open set, and let θ=△(W1,b1,...,WL,bL)be the network’s parameters, with Wl∈Rdl×dl−1,bl∈Rdl, and dL=1.We denote the corresponding ReLU network by hθ:Z→R, whereσ is a ReLU fucntion.hθ=△hθL∘σ∘hθL−1∘⋯∘hθ1,and hθl(z)=W1⋅z+bl. For 1≤l≤k≤L, we also introduce notation for truncated networks,hθl:k=△hθk∘σ∘hθk−1∘⋯∘hθl.We will omit the subscript θ when it is clear from the context. 위 정의에서 알 수 있듯이 이 논문에서 말하는 ReLU network 는 가장 단순한 형태의 네트워크입니다. 모든 이전 레이어의 모든 노드를 활용하여 현재 노드값을 계산하고, Residual 과 Recurrent 등이 없는 가장 단순한 형태의 네트워크입니다.
General ReLU network 는 특수한 성질을 만족하는 ReLU network 로, 연구에 용이하다고 합니다. 간단하게 말하면 general ReLU network는 모든 truncated network 가 서로 다른 입력 값에 대하여 서로 다른 출력이 나오도록 하는 네트워크입니다. 아래 명제에서는 truncated network 표현에서 θ 가 생략되고, 노드 위치를 나타내는 i,j 가 추가되었습니다. General ReLU network is one that satisfies the following three conditions.1. For any unit (l,i),the local optima of hi1:l do not have value exactly zero.2. For all k≤l and all diagonal matrices (Ik,...,Il) with entries in{0,1},rank(IlWlIl−1⋯IkWk)=min(dk−1,rank(Ik),...,rank(Il−1),rank(Il))3. For any two units (l,i),(k,j), any linear region R1⊆Z of hi1:l,and any linear region R2⊆Z of hj1:k, the linear functions implementedby hi1:l on R1 and hj1:k on R2 are not multiples of each other. 추가로, Transparent ReLU network를 정의합니다. Transparent ReLU network 는 어떤 입력이 들어와도 모든 레이어에서 적어도 하나의 노드 값은 active 되는 성질을 갖는 네트워크입니다. 대괄호는 정수 집합을 의미합니다. 예를 들어 [3] 은 1,2,3 으로 이루어전 집합을 의미합니다.
Transparent ReLU NetworkA ReLU networkh:Z→R is called transparent if for all z∈Z and l∈[L−1],there exists i∈[dl] such that hi1:l(z)≥0. ReLU network 와 관련된 정의를 마쳤습니다. 이제 논문에서는 위 정의를 바탕으로 논리를 전개해나갑니다.
Fold Sets 라는 새로운 개념을 제시합니다. Fold Set 은 그 이름에서 유추할 수 있듯이 공간이 접히는 부분으로, ReLU 함수를 생각해보면 x=0 에서 출력값이 접힙니다. Fold Set 는 ReLU 함수의 접히는 부분을 보다 일반화하여 표현한 것이라고 할 수 있습니다.
Fold SetDenoted F(f), defined as {z:z∈Z and f is non-differentiable at z} 또한 주어진 ReLU network 가 위에서 정의한 'general' ReLU network 이면서 'transparent' ReLU network 라면 아래 정리가 성립합니다. 즉, 각 레이어의 각 노드 값이 0이 되는 모든 입력값의 집합이 Fold Set 이 됩니다.
보조정리1Ifh:Z→R is a general and transparent ReLU network, thenF(h)=l,i⋃{z:hi1:l(z)=0} 아래 그림은 Fold Set 을 각 레이어 별로 구분지어 표현한 예시입니다. 예를 들어 첫 레이어에서는 가장 왼쪽 세 개의 선의 Fold Set 으로 인식됩니다. 이후 두번째, 세번째 레이어에서는 각각 주황 선과 검은 선이 Fold Set 으로 인식됩니다. Fold Set 은 주어진 모든 선을 합친 집합으로, 가장 오른쪽 그림의 모든 선과 같습니다.
논리 전개를 위해 추가적인 개념을 정의합니다. Piece-wise Hyperplane, Piece-wise linear surface 를 정의합니다. 이 개념을 이해하기 위해서는 파티션(Partition) 이라는 개념을 필요로 합니다. 파티션은 주어진 집합을 여러 개의 부분집합으로 나눈 것입니다. 파티션에 포함된 각 부분집합은 서로 공통된 원소를 갖지 않고, 각 부분집합을 모두 합치면 원래의 집합이 되어야 합니다.
Piece-wise Hyperplane 은 파티션의 특정 원소, 즉 부분집합에 대하여 레이어 연산이 0이 되는 입력값의 집합을 의미합니다. 위 그림에서 찾아본다면, 꺾이지 않는 각 직선 하나하나가 파티션이 주어졌을 때의 piece-wise hyperplane 이라고 볼 수 있습니다.
Piece-wise HyperplaneLet P be a partition of Z.We say H⊆Z is a piece-wise hyperplane withrespect to partition P, if H is nonempty and there exists (w,b)=(0,0)and P∈P such that H={z∈P:w⊺z+b=0} 위 정의에서 확인할 수 있듯이 Piece-wise Hyperplane 은 네트워크, 또는 레이어 중첩과 직접적인 연관이 없습니다. 파티션이 주어졌을 때 해당 파티션을 쪼개는 직선이 Piece-wise Hyperplane 입니다.
반면 Piece-wise Linear Surface 는 네트워크 및 레이어 중첩과 보다 직접적인 연관이 있습니다. Piece-wise Hyperplane 은 파티션이 주어졌을 때 정의되는 반면, piece-wise linear surface 는 파티션을 이전 레이어의 piece-wise hyperplane 에 따라 재귀적으로 정의함으로 레이어 중첩을 강조했습니다.
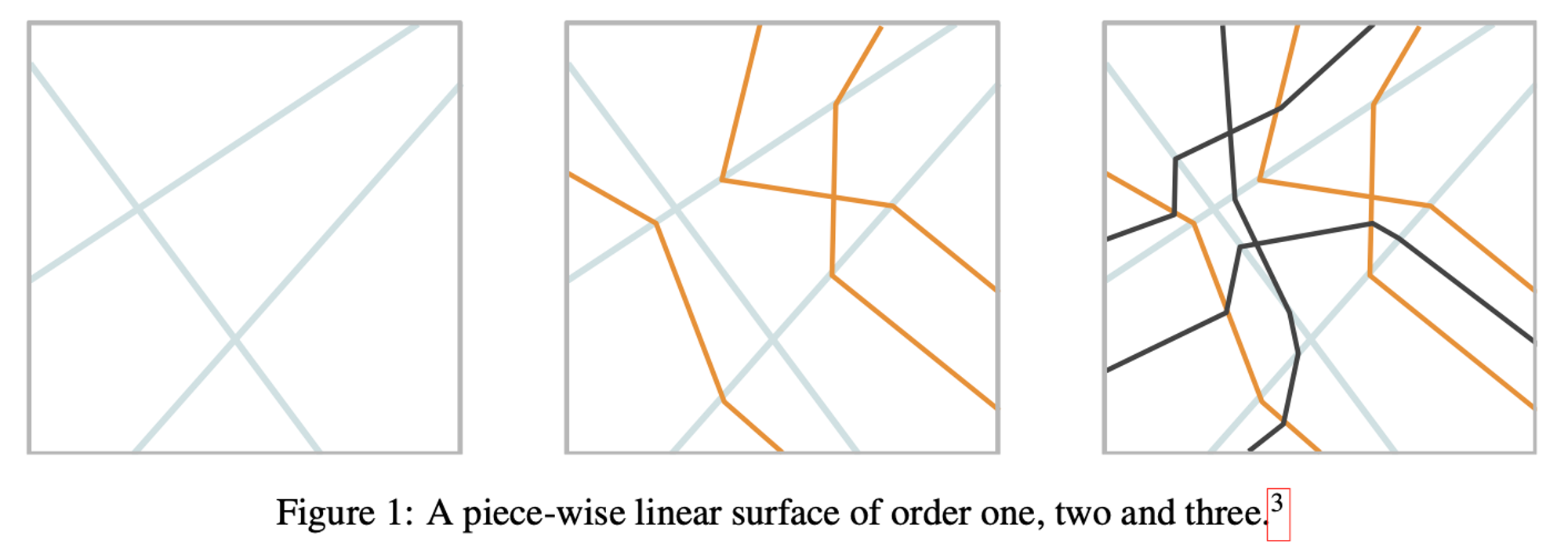
Piece-wise Linear SurfaceA set S⊆Z is called a piece-wise linear surface on Z of order κ if it can bewritten as S=⋃l∈[κ],i∈[nl]Hil where each Hil is a piece-wise hyperplanewith respect to PZ(⋃k∈[l−1],j∈[nk]Hjk), and no number smaller than κ admits such a representation. 위 정의를 이해하기 위해 PZ(⋃k∈[l−1],j∈[nk]Hjk) 를 이해해야 합니다. 이 기호는 괄호 안에 있는 집합으로 partition 을 생성한다는 의미로, Figure 1 그림을 예시로 들어 설명드리도록 하겠습니다. 처음 레이어를 거치지 입력 집합 Z는 아무런 구분이 없습니다. 그러나 레이어를 하나 통과함으로써 가장 왼쪽의 그림처럼 세 개의 파란색 선이 생성되고, 각각의 선이 piece-wise hyperplane 이 됩니다. 이에 따라 전체 집합은 자연스럽게 6개의 부분집합으로 쪼개집니다. 이제 두 번째 레이어를 거치게 되면 가운데 그림처럼 주황색 선이 생깁니다. 주황색 선은 첫번째 레이어에 따라 주어진 6개의 각 부분집합 안에서 직선으로 이루어져 있음을 알 수 있습니다. 이제 파란색 선에 주황색 선이 추가됨으로써 전체 집합은 16개로 쪼개짐을 확인할 수 있습니다. 이렇듯 레이어 중첩에 따라 쪼개지는 모양을 PZ(⋃k∈[l−1],j∈[nk]Hjk) 로 표현한 것입니다. 또한 κ 가 하는 역할 역시 중요합니다. 예를 들어 파란색 선과 주황색 선의 집합은 하나의 레이어만 거쳐서는 생성할 수 없습니다. 최소 두 개 이상의 레이어를 거쳐야지만 생성할 수 있습니다. 따라서 가운데 그림에 그어진 전체 선의 집합은 piece-wise linear surface of order 2 입니다. 이 예시를 보다 일반화하여 아래 보조 정리가 성립합니다. 보조정리2If h is a general and transparent ReLU network, then its fold-set is a piece-wise linear surface of order at most L−1. Piece-wise linear surface 를 보면 결국 레이어를 쌓아감에 따라 재귀적으로 정의되고, 계산할 수 있음을 알 수 있습니다. 이번에는 반대로, Piece-wise linear surface 가 하나의 집합으로 주어졌을 때 어떻게 레이어를 구분할 수 있는지에 대해 다룹니다.
아래의 오른쪽 그림처럼 Piece-wise linear surface 가 주어졌을 때, 왼쪽 그림처럼 레이어를 구분하기 위해 PZ(⋃k∈[l−1],j∈[nk]Hjk) 와 유사한 방법으로 아래와 같은 구분 절차를 제안합니다. 1.
전체 집합에서의 모든 hyperplane, 즉 꺾이지 않는 모든 직선을 첫 번째 레이어로 할당한다.
2.
1. 의 절차에 따라 첫 번째 레이어에 할당된 hyperplane 에 의해 자연스럽게 구분되는 파티션이 생성된다. 각 파티션 집합 내에서 꺾이지 않는 모든 직선을 두 번째 레이어로 할당한다.
주의해야 할 점은 이러한 레이어 구분 절차를 사용하면 원래 레이어 구조로 복원되지 않을 수 있다는 점입니다. 예를 들어 위의 왼쪽 그림에서 보면 파란색 선과 주황색 선은 둘 다 올곧은 직선이기 때문에 구분되지 않습니다. 따라서 파란색 선과 주황색 선 모두 첫번째 레이어에 할당될 것이며, 검은색 선만이 두번째 레이어에 할당될 것입니다. 그러나 원래대로 복원되지 않을 수 있다는 점은 논리 전개에 있어 큰 문제가 아니므로 이후 과정을 진행합니다.
이제 Piece-wise linear surface 가 주어졌을 때 레이어를 구분할 수 있게 되었습니다. 즉 전체 네트워크 h가 주어졌을 때 truncated network 인 h1:k를 알 수 있게 된 것입니다. 따라서 아래와 같은 기호를 추가적으로 정의합니다. For a piece-wise linear surface S,□kS:=⋃{S′⊆S:S′ is a piece-wise linear surface of order at most k} 위 정의에 따라 truncated network, 또는 □kS 역시 piece-wise linear surface 임을 알 수 있습니다. 또한 한가지 중요한 특성이 존재하는데, □kS 를 구성하는 각각의 piece-wise linear hyperplane 이 서로 공통되는 부분이 없는 반면 모두 다 합치면 다시 □kS 이 생성된다는 점입니다. 따라서 □kS 는 유일하게 ⋃l∈[k],i∈[nl]Hil 로 표현할 수 있습니다. 이렇듯 주어진 값을 유일하게 표현할 유일하게 표현하는 경우에 canonical representation 이라고 표현합니다. 이제 Dependency Graph 를 정의하기 위한 준비가 끝났습니다. Dependency Graph 는 레이어가 중첩됨에 따라 나타나는 Piece-wise hyperplane 사이의 관계를 나타내는 그래프입니다.
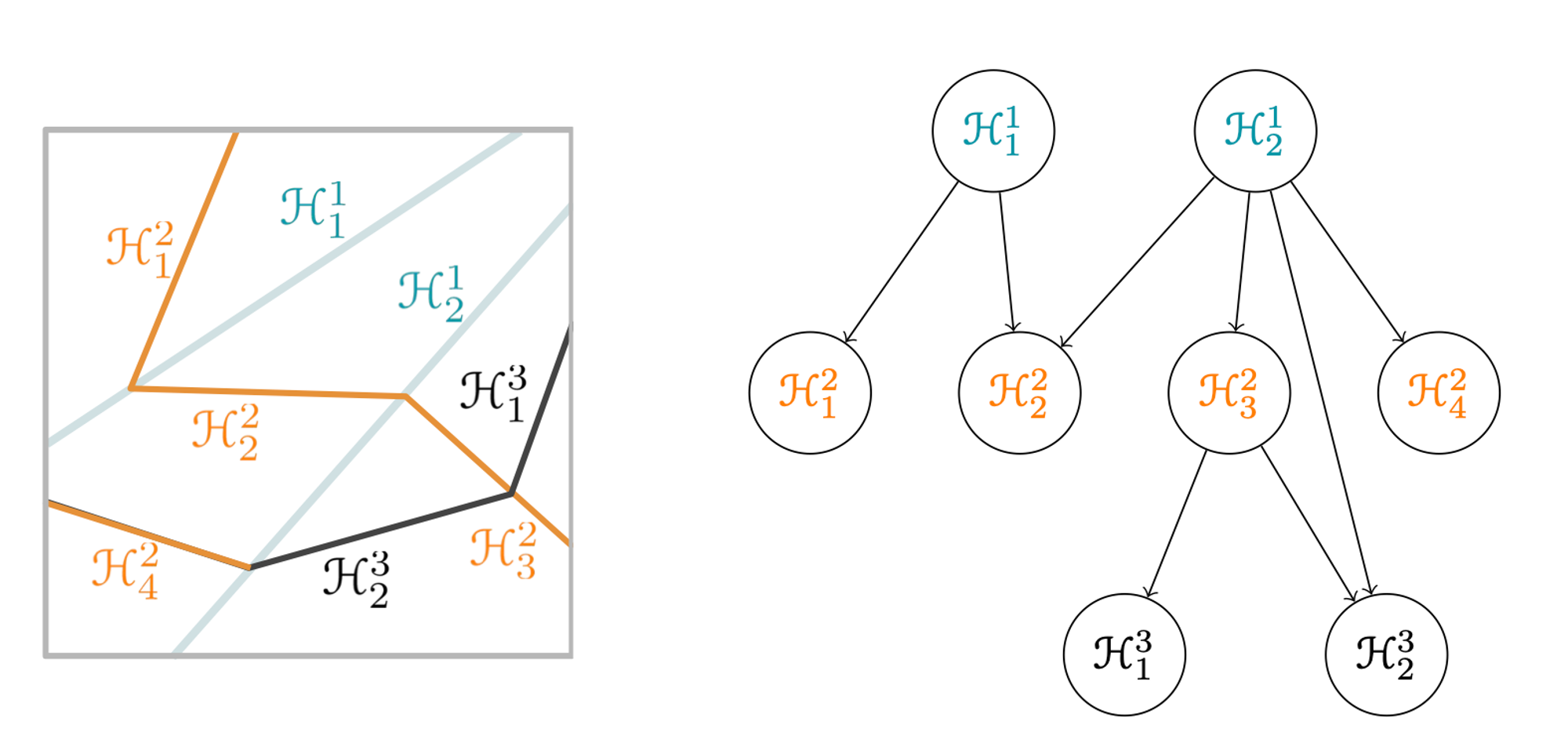
Dependency GraphLet S=⋃l∈[κ],i∈[nl]Hil be the canonical representation of S.The dependency graph of S is the directed graph that has the piece-wise hyperpalnes{Hil} as vertices, and has an edge Hil→Hjk iff l<k and relint Hil∩cl Hjk=∅.That is, there is a edge Hil→Hjk if Hjk ‘depends on’ or ‘bends at’ Hil. 아래의 왼쪽 그림처럼 Piece-wise Hyperplane 이 주어졌을 때의 Dependency graph 는 오른쪽 그림과 같이 표현됩니다. 첫 번 째 레이어의 H21 는 두번째 레이어의 H22,H32,H42 와 접하고, 세번째 레이어의 H23과 접합니다. 따라서 오른쪽 그림처럼 간선을 작성합니다. 반면 H42 역시 H23 과 접함에도 간선을 긋지 않습니다. 그 이유는 우선권이 더 낮은 레이어에 있기 때문입니다. 똑같은 점에서 여러 hyperplane 이 접한다면, 우선권은 저층의 레이어에 주어집니다. 이제 Dependency Graph 를 활용하여, 아래 두 개의 보조 정리를 증명할 수 있습니다.
보조정리3Let h:Z→R be a general ReLU network.Denote S:=⋃l∈[λ],i∈[dl]{z:hi1:l(z)=0} and let S=⋃k∈[κ],j∈[nk]Hjk becanonical representation of S. Then for all Hjk there exists a unit (l,i) with l≥ksuch that Hjk⊆{z:hi1:l(z)=0}.Moreover, if the dependency graph of S contains a directed path of length mstarting at Hjk, then l≤λ−m. 보조정리4For a bounded open nonempty domain Z and architecture (d0,...,dL)with d0≥d1≥⋯≥dL−1≥2,dL=1. There exists a general transparent ReLUnetwork h:Z→R such that for l∈[L−1], the fold-set F(hl:L∣int Zl−1) isa piece-wise linear surface whose dependency graph contains dl directed paths oflength (L−1−l) with distinct starting vertices. 보조정리 3은 네트워크의 Dependency 에 대한 정리이고, 보조정리4 는 general transparent ReLU network 가 갖는 Dependency graph 의 특성에 대한 정리입니다.
이제 Result 를 증명할 준비가 되었습니다. 증명은 만약 두 네트워크의 Fold Set 이 같다면, 각 레이어가 만드는 Fold set 의 한 부분 역시 같을 수 밖에 없음을 증명합니다.
예를 들어 두 네트워크의 Fold Set 이 아래 그림과 같을 때, 두 네트워크 모두 파란색 선이 첫 번째 레이어에서 만들어질 수 밖에 없음을 증명합니다. 또한 같은 파란색 선이 만들어지기 위해서는 두 네트워크의 첫번째 레이어가 서로 Permutation Matrix 와 Positive Diagonal Matrix 로 관계될 수 밖에 없음을 증명합니다.
이후 수학적 귀납법을 사용해서 주황색 선이 두 네트워크 모두 두번째 레이어에서 발생할 수 밖에 없음을 증명하고, 위 과정을 반복합니다. 그럼으로써 위에 소개했던 Result 에 대한 증명이 완료됩니다. Sketch 이므로 간단하게 기술했지만, 사실 위 명제를 증명하기 위해 필요한 약 스무개의 보조정리가 논문 Appendix 에 수록되어 있습니다.
저는 논문을 읽기 전에는 이 논문이 over parametrization 에 대해 다루는 논문으로 알았습니다. 물론 어느정도 연관되어 있긴 하겠지만, 읽고나니 오히려 ReLU Network Equivalence 를 다루는 논문으로 느껴졌습니다. 다양한 수학적 개념을 도입하여 논리를 전개하는 것이 흥미롭게 다가왔습니다. 사실 수학적인 증명에 관한 것이므로 현실적으로 쓰일 일은 없겠지만, 그래도 이런 다양한 관점에서 네트워크를 해석하려고 하는 시도가 모여 발전이 이루어지지 않나 하는 생각도 듭니다.
이 글은 제가 일하고 있는 크래프트테크놀로지스의 지원을 받아 작성되었습니다.
다양한 연구들을 어떻게 금융 도메인에 연결시킬 수 있을까 항상 재미있게 고민하고 있습니다. 함께 공부하고, 멋진 전략 혹은 서비스까지 이어가실 분들은 아래 링크를 참조해주세요